Michael Callahan Phil Schwan In the last few years Linux has established itself as a very successful
alternative to conventional operating systems as a fast platform for file
and web servers. This can be attributed to the incredibly fast rate
of development and improvement of the networking and file system support
code in the Linux kernel.
But support for multimedia hardware is still far behind that for
other operating system, sometimes due to the lack of support and documentation
by hardware manufacturers, sometimes due to licensing problems (most notably with DVD).
Another major reason for this was the lack of a standardized programming interface.
Although from early on there were some Linux drivers for multimedia cards
available they usually came with their own set of ioctls and their own
application which would only work with this one card.
In 1997, Alan Cox introduced the Video4Linux API to the 2.1.x series of
kernels. It acts as a layer between a low level device driver and the user application.
The basic idea is that once the device driver registered itself with the Video4Linux
layer it can be used by the user application via the Video4Linux API ioctls.
Thus, any application which is fully conforming to the Video4Linux standard (I admit
that not all do this FULLY) should be able to use any Video4Linux conforming device
driver.
In the beginning, Video4Linux only provided support for bttv and the Quickcam
parallel port cameras. Since then it has come a long way.
In the latest 2.3.x kernels the support ranges from radio cards, over TV cards
to MJPEG cards. Other separately available drivers which use the Video4Linux
standard (in a slightly modified form) even include an MPEG2 decoder card.
But Video4Linux also still has to go a long way to become a full-fletched
Video API which can support all kinds of multimedia hardware.
The current version is e.g. not very flexible regarding capturing of video streams
and is still very much influenced by the specific features of the bttv driver.
The next version of the API, Video4Linux2, is much more flexible and was also
designed with the support of new hardware like MPEG encoders in mind.
My talk will be roughly structured like this:
A Logical Volume Manager (LVM) is a subsystem for on-line disk storage
management which has become a de-facto standard accross UNIX implementations.
It adds an additional layer between the physical peripherals and
the i/o interface in the kernel to get a logical view of disks.
Unlike current partition schemes where disks are divided into
fixed-sized sections, LVM allows the user to consider disks, also known as
physical volumes (PV), as a pool (or volume) of data storage,
consisting of equal-sized extents.
A LVM system consists of arbitrary groups of physical volumes,
organized into volume groups (VG). A volume group can consist of one or more
physical volumes. There can be more than one volume group in the system.
Once created, the volume group, and not the disk, is the basic unit of data
storage (think of it as a virtual disk consisting of one or
more physical disks).
The pool of disk space that is represented by a volume group can be
apportioned into virtual partitions, called logical volumes (LV) of
various sizes. A logical volume can span a number of physical volumes
or represent only a portion of one physical volume. The size of a
logical volume is determined by its number of extents. Once created,
logical volumes can be used like regular disk partitions - to create a
file system or as a swap device.
The talk includes a demonstration of basic usage szenarios of the LVM
including the initialization of physical volumes and setup of volume groups.
Logical volumes will be created and resized. Extents will be moved
between phyiscal volumes to show the non interrupting way this happens.
An illustration of the basic metadata structures, the implementation of
the driver, some essential tools and library functions finishes the talk.
The Advanced Linux Sound Architecture (ALSA) [1] project is
originated from the Linux Ultra Sound Project [2]. The original
project was intended only for Gravis UltraSound soundcards. The ALSA project
extents this effort for all soundcards and sound APIs.
The main goals of the ALSA project are:
The ALSA driver uses a quite different look to the devices than the OSS/Free
[3] driver. The primary identification element is a soundcard.
The devices for one interface - like PCM (digital audio) - are not mixed
together. Each soundcard has its own set of devices. The ALSA driver
identifies devices via two numbers: a soundcard number and a device number.
This representation is more real and an user understands the device mapping
in an easier way.
The ALSA driver is very modularized. We are trying to separate every things
to independent modules. This separation has big advantages:
Example #1 - dummy driver:
Example #2 - Trident 4D-Wave DX/NX driver:
An example of some possible mixer part:
This part contains six mixer elements:
The mixer group 'Line' has only elements, which can be driven:
The mixer API is able to pass the changes (value or structure based) to
an application to preserve consistency among more mixer applications and
to notify the mixer structure changes.
The ALSA driver has two features, which are not in OSS/Free. The full
duplex feature allows that one PCM device may be used with two independent
application. One application may use the PCM device for playback (output)
and second for capture (input). The most recent feature is 'multi open'.
Some sound chips are able to mix more PCM streams in hardware. The multi
open feature allows to open one PCM device more times, until all resources
are not exhausted.
More changes are upcoming inside ALSA PCM API:
The ALSA driver also contains the full support for ISA Plug & Play cards.
The new isapnp module is not designed only for soundcards, but it can be
used with an another driver for an ISA Plug & Play card. This slightly
modied code (to follow Linus requests) is present in the 2.3.14 kernel.
The ALSA C library fully covers the ALSA driver API. The ALSA library extents
the driver functionality and hides the kernel calls.
The interfaces are closely before completion. We are working on the PCM API
enhancements and the native sequencer in the driver. The drivers for wavetable
chips are also in development. We also need to write the documentation for
application and lowlevel driver programmers.
The ALSA team hopes that the ALSA driver will be merged into the main kernel
tree after all application interfaces will be stable. Alan Cox partly
confirmed this fact. We expect that OSS/Free and ALSA drivers will coexist
together for a while. When ALSA becomes fully featured, OSS/Free may be
removed from the Linux kernel.
Jaroslav Kysela is the founder and current leader of the ALSA project.
He has been working with Linux since 1993. Between 1994 and 1997 he worked
on the Linux Ultra Sound Project. In 1995 he initiated and still maintains
the development of the driver for 100Mbit/s Voice Any Lan network adapters
from Hewlett Packard (the hp100.c driver). Since 1998 he has been working
on the ALSA project. He was hired by SuSE GmbH [5] in April 1999.
[1] Advanced Linux Sound Architecture - http://www.alsa-project.org SGI is porting is world class XFS file system to Linux. XFS is a full
64-bit file systems that can scale to handle extremely large files and
file systems. Some XFS features include:
This talk will describe the architecture and implementation of XFS
and discuss the Linux porting effort.
Author:
Jim Mostek is the technical lead of the XFS Linux port at SGI. Jim has a
Math and Computer Science degree from the University of Illinois. He has
over 18 years of extensive experience in file systems and networking
including:
Jim's primary experience has been with UNIX based systems of various flavors
including BSD, PWB, and SystemV, IRIX, and UNICOS. With desktop environemnts like KDE and GNOME these days Linux becomes more and more
popular as desktop system too. But a nice desktop without applications is
quite useless. So desktop applications are urgently needed. The KOffice will
provide such a set of applications.
The desktop applications, which are mostly used (like wordprocessors,
spreadsheets, presentation Applications, etc.) are normally bundled together to an
Office Suite. Today companies like Stardivison, Corel and ApplixWare offer their Office
applications for Linux too. Some of them even provide a private edition which everybody can
download without paying for it. So, why do we need another Office Suite like the KOffice?
There are some good reasons. First of all, the Office Suites I mentioned above, are not free.
This means the sources are closed. In contrast to that the KOffice and all its sources are free -
it's under the GNU General Public License. Besides the advantage that everybody may change and
redistribute the sources, people which are working on not so popular systems (like Alpha Linux,
Sparc Linux, etc.) can just compile the sources on that system too and don't need to wait until
a company maybe supports the certain hardware platform.
But there is one more important reason. If we look at the existing Linux Office Suites, we see that
they don't cooperate with others. So it's e.g. not possible to use the spreadsheet of one
Office Suite in the wordprocessor of another. It's most of the time not even possible to
exchange data between different Office Suites via drag'n'drop.
So the KOffice team developed a free object model (KOM/OpenParts) based on the industry
standard CORBA. Using this object model you cannot only embed KOffice applications into others but
also other applications, which use the OpenParts object model, will be able to cooperate
with KOffice and other OpenParts applications. E.g. the whole KDE 2.0 desktop is built upon this object
model to make it as flexible as possible. If one day somebody writes a better chart engine
than KDigramm using the OpenParts model, it's e.g. possible to visualize the data of
KSpread with this new digramm engine.
But which applications are already included in the KOffice? There is KSpread, an
extensible spreadsheet application, which was also the first KOffice program.
KWord is the wordprocessor of the KOffice. In contrast to most of the availabe wordprocessors,
it's framebased like FrameMaker and Ami Word. But it's also possible to use it page orientated
and for simple tasks like writing letters. The presentation application of the KOffice, called KPresenter,
allows to create screenpresentations, printed presentations and HTML slideshows. There is also a
quite advanced vector drwing program, named KIllustrator, included in the KDE Office Suite. To be able
to embed pictures into applications, which don't support that (like KSpread), there
is an image viewer, which also offers simple image manipulation functions, called KImage.
KDiagramm, which is mostly used as embedded part too, allows to visualize data with lots of different
chart types. It also works perfectly together with KSpread. Then there is the formula editor KFormula,
which also is most useful as an embedded part. The youngest member of the KOffice is Katabase, a
database application, which is in a very early development state.
One feature, that made Office Suites like the Microsoft Office very successful and
popular is scripting, which makes the Office applications extensible (in this case VBA).
So originally the KOffice team started to make the KOffice scriptable with Python. But
after some problems with Python, we decided to write a new scripting language, called KScript.
The syntax is very much like Python, but as KScript is designed for the KOffice and the OpenParts
object model, it's easier to integrate this into the KDE Office Suite. So it's already possible
to extend KSpread using KScript - the other KOffice components will follow.
Another very important thing for exchanging data between different applications and Office
Suites are file filters. So the KOffice provides a very flexible filter architecture -
all filters are standalone applications. A filter gets the data of a file, the mime type of that
file and the mime type of the file, which the filter should return. But a nice architecture without
working filters doesn't help a lot. So there are already ASCII and HTML import and export filters for
KSpread and KWord, and KIllustrator can read XFIG files. Also people are working on a RTF and a WinWord
filter for KWord and a MIF filter (FrameMaker) for KWord has been started too. As native file format
all KOffice applications use XML, which allows to edit KOffice documents in a texteditor too.
As nobody is able to write Office applications in a very short time, such a development takes a lot
of time. Version 1.0 of the KOffice will be distributed together with KDE 2.0. A first beta may be
expected in autumn 1999. Reiserfs is a file system using a variant on classical
balanced tree algorithms. The results when compared to the ext2fs
conventional block allocation based file system running under the same
operating system and employing the same buffering code suggest that
these algorithms are more effective for large files and small files not
near node size in time performance, become less effective in time
performance and more significantly effective in space performance as one
approaches files close to the node size, and become markedly more
effective in both space and time as file size decreases substantially
below node size (4k), reaching order of magnitude advantages for file
sizes of 100bytes. The improvement in small file space and time
performance suggests that we may now revisit a common OS design
assumption that one should aggregate small objects using layers above
the file system layer. Being more effective at small files DOES NOT
make us less effective for other files, this is a general purpose
FS.
Hans Reiser will also discuss whether filesystems are semantically
impoverished compared to database and keyword systems, and whether that
should be changed. It is difficult to use and to program for the Unix enviroment. This lecture
tries to find out why. There are three areas:
Indeeds you can find huge deficencies in all three areas. The lectures points
out these in the kernel space.
kernel space:
Frank Klemm studied physics at the university of Jena. Currently he is a
DSP programmer at Carl Zeiss Jena. He has worked with Linux since 1996. Since February 1998, HPLabs has been working to port Linux to the
IA-64 IA-64 is more than just another architecture. It introduces a new computing
paradigm called EPIC (Explicitly Parallel Instruction Computing) which
means that it exposes instruction level parallelism to the user. This new
architecture has massive amount of resources with 128 general registers
as well as 128 floating point registers. It also provides very advanced
features like instruction bundling, a register stack engine (RSE) to avoid
saving registers on procedure calls, predication to minimize the number of
branches, speculation to hide memory access latency and rotating registers for
software pipelining. In the full paper, we intend to give simple examples with
actual code sequence for each feature.
Porting the Linux system to a new architecture involves significantly more
than just getting a kernel. A complete port requires a
development tool chain, a kernel and thousands of user level applications
and libraries. The lack of near-term IA-64 hardware platform make this port
even more challenging as we're required to use a simulation
environment.
The first step was to put together the development tools.
Linux and especially its kernel are heavily dependent on a GNU C compatible
compiler. Such tool did not exist, so we decided to work on it first. The
obvious candidate was egcs, a very active branch off the gcc
development tree. We also ported the gas package to get an assembler,
linker and associated binutils.
Writing an optimizing compiler for EPIC is
not a trivial task and would have required changes to the egcs
front-end and, as such, was out of the scope of our project. Instead, we built
a back-end for egcs that would produce functional code for now.
The tool chain uses the standard ELF64 defined for IA-64 as the
object file format and follows the LP64 (longs and pointers are 8 bytes)
programming model. By September, the tool chain was able to pass the
egcs test suite and generate the classic ''Hello World''
program correctly. In the final paper we intend to give more details about
this first phase of our work.
We are using an instruction set simulator for execution of IA-64 code.
This means that we only simulate the full IA-64 instruction set of the CPU
and not the whole platform (e.g. no PCI bus nor BIOS). The simulator provides
hooks to get I/O services from the host system. It supports two modes of
simulation: user-mode or system mode. The former allows to run user-level
applications and it traps into the simulator for system call emulation.
In system mode, kernel bring up is possible as the full VM and interrupt
behaviors are simulated. We'll describe the work we've done to host this
simulator on Linux, and how we've emulated devices like a disk, serial
console and Ethernet.
Once the tool chain and simulator were in place, the full development
environment was available on Linux/x86 and work on the kernel could really
begin.
We decided to do a straight port of the Linux kernel and
minimize modifications to the machine independent part.We also chose to keep
track of the latest kernel versions (we started with v2.1.126 and
are now using v2.3.X) as this would make the final integration stage
much smoother. The kernel is running in native 64bit mode and uses
little-endian byte ordering for obvious compatibility reasons with x86. The
default page size is 8KB (may evolve as we move forward).
We took the incremental approach of bringing up subsystems one by one.
We began with start_kernel() and then added missing pieces as
they became required. We started in late October and ever since we have
been enabling key components like VM, interrupts, context switches, system
calls,etc. We developed a series of simulated device drivers which would trap
into the simulator to get I/O access. We built a SCSI driver (simscsi), a
serial driver (simserial) and an Ethernet driver (simeth)
which we'll describe in more details in the final paper. By January 1999, we
were able to execute our first "Hello world" program in user-mode. At that
time, we did not have a full C library so recompiling existing commands was
not possible. Instead, we had a "µ" which we used to rewrite
simple tools like a tiny shell (tsh) and commands like ls,
cp, cat, mount, halt, etc.
In early March, the network stack was up and running and we could ping in & out
or remote login into the simulated kernel. Shortly thereafter, the signal
handling and ptrace() support were also in place. We even got strace
working, which helped with debugging. Today, most of the key components exist
and the kernel is complete enough that we can now run actual Linux commands from
standard distributions. In the full paper, we intend to give more details of
the kernel work and plan on showing actual code sequences that exhibits some
of the IA-64 features.
In the meantime,
CERN We quickly managed to rebuild a complete login sequence which typically includes
init, mingetty, login,passwd and a
shell. We used the standard RPM As more applications were being ported, the usability of our development
environment and system mode simulation speed became a real concern. User
applications don't necessarily require to run on the actual IA64-kernel, so
user-mode emulation is often just fine. Operating in a cross compilation
environment was annoying because most standard RPM packages are not really
constructed to be recompiled that way. Fixing the Makefiles can be really
tedious as some applications use helper programs during the build phase.
For those reasons, we decided to work on getting what we called ''NUE''
(Native User Environment) which would give the illusion of a native IA-64
environment on our x86 host. This was very simple to achieve when combining
our simulator (user-level mode) and Linux's binfmt_misc code inside
a chroot'ed tree. Now you can invoke standard x86 and IA-64 binaries directly
from your shell prompt. In this closed environment, as, cc,
ld, really are cross compilation tools but look like native.
The C library and include files are in their natural location. Thus,
it becomes very easy to rebuild RPM packages without changing one line
of Makefile: a simple rpm --rebuild suffices most of
the time.
As of today, we have a complete development environment and we can run either
on top of the Linux/ia64 kernel or in the NUE environment.
Most of the kernel is done but SMP, platform specific code, the boot-loader,
IA-32 emulation are still missing. At the user-level, the C library still
needs more work and dynamic linking is in progress.
On the application front, required packages like gdb,
Xfree server, Java, Mozilla, GNOME/KDE
need to be ported. Lots of opportunities for EPIC-style optimizations
are available in assembly code but also in C code and as the tool chain improves
we hope too see major performance boost. We're also collaborating with other
industry partners like Cygnus, Intel, SGI and VA Linux Systems
to make sure we get the best possible Linux system available from day one.
1 See http://www.hp.com/go/ia64
2 Centre Européen de la Recherche Nucléaire -- Geneva, Switzerland, see http://www.cern.ch/
3 RedHat Package Manager, see http://www.rpm.org
The Debian distribution now supports seven different architectures,
but the package maintainers usually only compile binary versions for
i386. Developers for other architectures have to watch out for new
versions of packages and recompile them if they want to stay
up-to-date with the Intel distribution.
As Debian/m68k (the first non-Intel port) started, all this was done
manually: One watches the upload mailing list for new packages and
takes some of them at home for building. Coordination that no package
is built twice by different people was done by announcing on a mailing
list. It's obvious that this procedure is error-prone and
time-consuming. This has been the usual way for keeping non-i386
distributions current for a long time.
The build daemon system automates most of this process. It consists of
a set of scripts (written in Perl and Python) that have evolved over
time to help porters with various tasks. They have finally developed
into a system that is able to keep non-i386 Debian distributions
up-to-date nearly automatically.
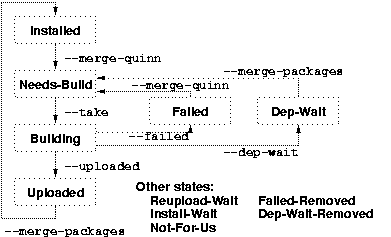
The buildd system consists of the following main parts (see
also figure 1):
At the heart of the system is the wanna-build database, which
keeps track of package versions and states. quinn-diff
compares the package lists for i386 and the target architecture every
day and feeds a list of packages that need re-compilation into the
database where they enter state Needs-Build.
All the build daemons (there can be more than one) query the database
regularly for such packages and take some of them so that they go
into state Building. Of course, humans also can take
packages, e.g. in special cases where automatic compilation isn't
possible. Here we also see the second purpose of wanna-build:
It ensures that the same version of a package won't be built twice.
If everything goes well, a finished package can be uploaded later,
which is another state Uploaded. After that it will
eventually be installed into the Debian archive so it appears in the
updated package list for the target architecture. This list will be
merged into the database, so the package will go to state
Installed and remains there until the next i386 version.
There are several other states; they include: Failed is for
packages that failed to build due to errors in the sources, and the
errors are expected to be fixed in a successor version (after
reporting the problem, of course). So a new version will directly
enter Needs-Build, but with a warning that something was
wrong with the previous version. Along with this state an error
description is stored. State Dep-Wait is used when a package
needs some other packages to be compiled but those aren't available
yet and must be built before. This state stores a list of required
packages and maybe versions, and if all of them are known to be
installed the state changes back to Needs-Build.
As we have already seen, the build daemon takes packages from the
database for compiling them. Let's look a bit closer: If it has some
packages to build, it uses sbuild for the actual compilation
process, and for each build a log is mailed to the maintainer of the
daemon. He reviews the log and decides what to do with the package:
upload it, set it to Failed or Dep-Wait, make some
additions to the source dependency list and retry it, etc...
If a positive acknowledge is received, the daemon moves it to an
upload directory, from where all packages are uploaded by a cron job.
Looking at the log files is the only human intervention in the whole
process if no errors happen. There are two good reasons for not
further automating this: First, sometimes builds end with an ``OK''
result but the build nevertheless failed for reasons that are
invisible to the machine. And second, directly uploading would require
to automatically PGP-sign the resulting files with a key without
passphrase on the build machine. I considered this an unacceptable
security hole.
The build script sbuild more or less just calls some standard
Debian tools to compile the sources. It also helps with some common
tasks and bookkeeping, but the really special thing about it are the
source dependencies. Often packages need other packages installed for
compilation, for example compilers and libraries. It is not practical
to have all these packages installed all the time, and often it's not
even possible because of conflicts. The source dependencies now simply
tell sbuild for each package which other packages are needed.
It can then automatically install them before the build and remove
them again afterwards.
The source dependency list can partially be generated automatically,
too, by looking at the dependencies of the binary packages generated
by the source. This is andrea's job, which analyses the i386
package list for dependencies and maps library packages to development
package names. It also merges the results with manual additions for
things that can not be auto-generated, like compilers or special
tools.
At the moment four Debian architectures use buildd: m68k,
powerpc, alpha and sparc. m68k has even two daemons running, one for
the stable release level and one for the rest. And there are plans for
a buildd on sparc64 (UltraSparc).
The success of buildd in keeping a distribution up-to-date
most dramatically shows for m68k: This architecture has the slowest
machines, but only one daemon can keep pace with the i386 unstable
distribution by minimizing idle times and time-consuming manual
actions. In the past, we usually always were 200-300 packages behind
i386, but with the daemon this has decreased to less than 5% of all
packages, including failed and waiting packages.
Another application of buildd could be the maintenance of
distribution variants, like a Pentium-optimized version. This can be
seen as a new ``architecture''. It also would be no problem to, e.g.,
recompile only packages of a certain importance.
Another proposal is to run a buildd for i386. This makes
sense, as Debian now has some maintainers that have no i386 machine.
This, however, requires some changes first, because i386 is still
considered the reference architecture inside the system.
Most parts of the buildd system have been written by James
Troup and me. I also want to thank the other members of the
Debian/m68k build team (some, but not all: Chris Lawrence, Michael
Schmitz, Christian Steigies) and PowerPC porter Hartmut Koptein for
suggestions, ideas, and testing. Special thanks go to Stefan Gybas for
donating the 68060 accelerator board for kullervo, and last but not
least thanks to Martin ``Joey'' Schulze for hosting two of the
buildd machines, kullervo (m68k) and tervola (PPC).
For quite some time, the sendmail mail transport system was the epitome
of bad security -- every couple of months, somebody would find a bug or
misfeature what allowed local and occasionally even remote attackers to
obtain root privilege. Then, Java came along and Eric Allman was off the
hook for a while. Currently, the spotlight is on Microsoft because they're
new to the multiuser/network game, and their large installed base make
them an interesting target.
I have been actively involved in Linux security for at least four years
now; both in the role of blundering programmer, as someone catching other
people's blunders, and on various mailing lists. Linux' track record is
no better or worse than most of the other operating systems, but there's
definitely room for improvement.
The amazing news is that many programming mistakes that can lead
to security problems seem to be impossible to eradicate. For instance,
it has been a fairly well known fact for quite some time that special care
needs to be taken when executing another program from a setuid context.
However, there are still programs being written today that do not
take the proper precautions. The last case I came across was in May 1999,
and I'm sure it won't be the last.
There are probably many reasons why things are like this. Speaking
from my own experience as a blundering programmer, we tend to develop a
partial blindness when it comes to spotting trouble areas in our own code.
We're so much in love with our elegant design that we're reluctant to
anticipate all the ways in which an attacker might try to break it.
In addition, most security pitfalls -- the notable exception being buffer
overflows -- look harmless enough until you emph{know} how an attacker
might exploit them. Finally, many people underestimate the cleverness
of the cracker community. To most people, a cracker is a freaked-out 16
year old kid running scrounged up exploit programs they don't even half
understand. However, there's a non-negligible proportion of creative
hacker crackers who are well-educated in Unix (in many cases thanks
to Linux), and quite clever when it comes to finding the weak spots in
your software.
The focus of my talk will be on traps we tend to fall into, and how to
avoid them.
Olaf Kirch has been a member of Linux community since the 0.97 days.
He wrote the Linux Network Administrator's Guide, maintained the
NFS code for quite some time, and is currently employed by Caldera. Mosix is a software tool for supporting cluster computing. It consists
of kernel-level, adaptive resource sharing algorithms that are geared
for high performance, overhead-free scalability and ease-of-use of a
scalable computing cluster. The core of the Mosix technology is the
capability of multiple workstations and servers (nodes) to work
cooperatively as if part of a single system.
The algorithms of Mosix are designed to respond to variations in the
resource usage among the nodes by migrating processes from one node to
another, preemptively and transparently, for load-balancing and to
prevent memory depletion at any node. Mosix is scalable and it attempts
to improve the overall performance by dynamic distribution and
redistribution of the workload and the resources among the nodes of a
computing-cluster of any size. Mosix conveniently supports a multi-user
time-sharing environment for the execution of both sequential and
parallel tasks.
So far Mosix was developed 7 times, for different version of Unix, BSD
and most recently for Linux. Why be concerned with network security? The internet was created as a
government research network where it was assumed that no one was
hostile. It migrated to universities and other research institutions
that were not generally accessible to the public. Where it ran
through hostile areas, the hardware and physical carriers were
secured. While students started to gain access to such systems, it
sufficed to secure the exposed terminals and user interfaces.
Since then, it has exploded in use because the public started to gain
access to its resources: databases, bandwidth, connectivity. With
that have come a whole new breeds of internet users: commercial and
recreational. They see this as another whole resource to maximize,
externalizing their costs, at the cost of every other user.
Many of the commercial users treat it with the same regard they do the
natural world: less than respectful. Many of the recreational users
are not aware of the history, customs and 'nettiquette' on which it is
based. Because of all these factors, internet security has become
much more prominent, comprising of machine and network security. Many
are familiar with machine security, by limiting access to machines via
password logins and the importance of picking passwords that cannot be
dictionary attacked.
Network security is a more recent urgency, because packet sniffers are
now much more accessible to the public in the form of inexpensive or
free software packages that are able to turn common hardware into
useful passive and now active analysis tools. It is for these reasons
that network-layer encryption has become more and more important.
IPSec is a suite of RFC proposed standards that define a protocol for
packet-layer encryption.
Why use Linux? Linux is inexpensive, popular, and runs on a wide
variety of hardware and processor families. Proprietary kernels are
well documented, but not always documented correctly. Open-source
kernels are not particularly well documented, but that is changing.
The big advantage is that if something doesn't exist or doesn't work
as (not) documented, you can find out how to use it, or send a patch
to fix it.
What problems did I (we) have and how did we get around them? That is
the subject of this presentation after we get some basic concepts out
of the way.
Richard Guy Briggs got his taste of Un*x-like systems in 1990 while at
Corel Systems Corporation, testing interoperation issues with SCO ODT
1.0 on 80386, Solaris on a Sparc IPX and the 16-bit version of
Coherent on a 80286 and at the University of Ottawa on DEC Ultrix and
IBM AIX systems. The _Jargon File_ was a significant influence.
He has been working with Linux since version 0.13 when
he saw internet announcements about it on comp.ox.minix. He
subsequently used it to train the artificial neural network temporal
integrator for his 4th year undergraduate speech recognition project
in September 1992.
Two solar vehicle competitions later (one in the USA and one in
Australia), he started maintaining and porting device drivers for
ISA-bus telecommunications cards (T1, E1, ISDN) under SCO, UnixWare
and SolarisPC.
Richard has been maintaining and updating KLIPS, the FreeS/WAN kernel
module for that Linux IPSec implementation for 18 months.
For more background, see: http://www.conscoop.ottawa.on.ca/rgb/cv.html
or email him at: rgb@conscoop.ottawa.on.ca. More information
about FreeS/WAN can be found at http://www.xs4all.nl/~freeswan/. The gap between memory access time and hard-disk's seek time is becoming
bigger every year. The same holds true for CPU speed and hard-disk
speed. In this scenario, the traditional way of freeing pages in a
situation of memory shortage, which is saving some pages to disk,
is increasingly becoming problematic.
The alternative is to find an in-memory solution. One option is using
compression algorithms.
But both, the traditional and the compression approaches, share a common
disadvantage: If the process is accessing non-present pages, the operating
system must restore them and thus eventually needs to page out other
pages of main memory. Mergemem, in contrast, tries to increase the
amount of shared pages, thus allowing read-only access to the treated
pages without any overhead.
Today's operating systems, including Linux, are using page sharing
to save main memory. Code segments of executables and shared libraries
are shared by all processes, thus mapped to various VM spaces but
mapped only once to physical memory.
When a process calls fork(2), also the data segments (initialized data,
uninitialized data, heap and stack) are shared between the process
and the newly created child. If one of the two processes writes to
the shared area, the operating system is trapped and creates a private
copy for the writer (=copy on write).
Unfortunately a lot of processes running the same program do not have
the chance to share their data segments, because they are not created
by forking. Examples for this are in.telnetd processes created by
inetd, or xterms created by a window manager.
Another problem is that programs tend to initialize their data structures
in some way, thus the pages get copied for private use, but after
that initialization phase the pages actually carry the same contents.
A typical example of this problem is an interpreter building some
representation of an included file.
Mergemod is a character device which provides two important functions
to the system.
Thus mergemod is responsible for correctness.
We think that a stable API is as important as the systems itself, so
we designed the mmlib interface with the following goals in mind.
The interface should
Mergemem searches for equal pages and triggers the merging of these.
It turned out to be useful to have a single-shot mode and a daemon
mode of mergemem.
In order to facilitate the search for pages with equal contents, mergemem
calculates the checksums of all relevant pages and thus reduces the
search to finding equal checksums. We noted that the crc32 checksum
algorithm has a hit ratio of 100% in our tests, but we believe that
there is a cheaper checksum algorithm that delivers a reasonable hit
rate.
In the current implementation the search and checksum functions are
plug-ins and thus very easy to change.
Mergemem is responsible for efficiency.
From the view of the computer architecture, the effect of mergemem
is the same as that of operating systems using copy-on-write strategies.
Today virtually every architecture can deal with pages mapped to more
than one VM space in an efficient way.
When mergemem shares a page:
The amount of saved memory depends to a high degree on the running
applications. At a typical single user Linux workstation with only
two running xterms, besides the usual daemons, X, mingetty, etc.,
about 1 MB of memory is saved.
But since single user workstations require high administrative efforts,
there is a tendency to use central application servers in combination
with diskless terminals. In this environment, as was showed by our
prolog class, mergemem is able to double the available memory.
The 2.4 kernel will have significant enhancements in its networking
code. In particular, the masquerading, port-forwarding,
transparent-proxying and packet filtering systems have been formalized
on top of a framework called netfilter. Netfilter developer, Paul
"Rusty" Russell will describe in depth what this means for kernel
developers and users. The free Windows Emulator WINE is one of the longest standing projects
associated with Linux. While it is still in ALPHA development state, a
lot of windows applications already do start and are partially useable.
Started in 1993 as an attempt to run Windows 3.1 binaries on Linux most of
the work currently done is to implement the Win32 API on top of UNIX and
X11, with the goal to run Windows Binaries (16 and 32 Bit) and to provide
sourcecode compatibility for windows applications on UNIX platforms.
While WINE is no longer the way to get applications to Linux (there
already is a huge set of native ones), it is not obsolete. WINE is
needed for legacy applications (both 16 and 32 bit), applications that
won't be ported natively to Linux, be it due to political reasons,
lack of money or interest on the companies.
Speed of development has been increasing steadily over the last years,
but it increased by nearly an order of magnitude starting the involvement
of Corel which announced porting its Office Suite using WINELIB at the
end of 1998. With approximately 20 fulltime developers working on WINE
they contribute a rather large part of work on the additional libraries,
like OLE and Common Controls. Their goal is to have all of their Office
Suite Applications ported using WINELIB by the end of 1999.
A large part of the WINE developers (both volunteers and Corel employees)
are currently focusing on getting the Win32 core functionality working,
including multithreading, Win32 synchronization objects, and multiple
win32 process support. Others are working on replacements for Windows
DLLs, like OLE, Common Controls, DirectX, and Postscript Printer Support.
While it is difficult to give an estimate time of when WINE will
be finished, it can be said that by the end 1999 a large number of
applications will run sufficiently well to be able to use them.
The talk will give a brief introduction and historic overview over the
project, a technical introduction on how it is possible to run Win16
and Win32 binaries on a 32bit UNIX systems, followed by a report on the
current status of the project (including problems), some demonstrations
and should have room for questions and discussion. A lot of people know about NIS and NIS+ and use one or the
other for their daily work. For this reason, my talk will
not focus on how to install and configure it. Instead I would
like to talk about the underlying protocol, the advantages
and the problems of both NIS and NIS+. This should help the
user to solve problems faster. I will also tell something
about the current status of the NIS/NIS+ implementations
for Linux and my plans for the future.
At this point I will tell something about the different client
implementations for Linux (libc5, libc5+NYS, glibc) and the
daemons (ypbind/ypserv). I will also talk about the different
solutions for shadow over NIS and how ypserv can handle more
than one domain.
One disadvantage of NIS is, that we have only one central
master server. For every single change the whole map has to
be transferred to the slave, and an own table is needed for
every searchable column.
NIS+ is the successor of NIS and partially solves its problems.
On the client side we have a relatively good documenation, it
was not a big problem to implement the NIS+ functions for glibc,
on the contrary there is almost no documentation about the
protocols between two NIS+ servers and between the administration
tools and a server. We have only some names and parameters of the
RPC function calls.
Since there where a lot of changes for NIS+ from Sun, I will refer
to the current version in Solaris 7. I will explain the protocol
between client and server and how the Linux client finds the server.
Concering the security: NIS+ does not encrypt all the data it
should, but with GSSRPC we have now a solution for the much too
short keys of Secure RPC.
Future plans:
E-Commerce websites - the new challenge which we need to meet:
In the past, solutions like the Cisco LocalDirector, F5 BIG/ip and others have
been used to provide transparent load balancing between multiple servers.
However, besides the price tag, these solutions are all proprietary and often
do not fullfill all the demands at once.
I will present the problems and benefits encountered with Linux as a
webscaling solution. I will try not to focus tightly on the theoretical
aspects, but also point out the issues encountered in the field during actual
implementation and deployment.
The "Linux VirtualServer" project by Wensong Zhang now provides a useable
framework upon which sophisticated solutions can be build. Combined with the
advanced routing features of Linux, advanced packet filtering techniques and
the power of the freely available applications, Linux rivals and even exceeds
the most sophisticated solutions.
We are implementing such a solution for a customer. I will discuss the most
convincing arguments in favor of the Linux solution, give a summary of the
network and application design and then delve into the implementation process.
We will discuss the patches and tools used to build the redundant load
balancing system itself and the webservers. In particular, the load balancer
uses sophisticated network monitoring to intelligently distribute the load to
the servers, uses the heartbeat package to implement the HA failover,
automatically replicates the configuration to the hot-standby system and
out-of-band communications.
I will also comment on the various features which we found most useful in
implementing the whole cluster setup - content replication via CODA,
completely packaged systems, easy replacement of failed systems using a
KickStart mechanism, serial console remote control etc.
At the time of this abstract, the contract was just signed and you will be the
first to know the actual story, and especially the issues we had to solve on
the way. We will present first performance measurements and operational
results.
The final conclusion will be whether we made it or not. There are many theories that attempt to explain why people seem
comfortable doing things on the internet, such as writing software,
without getting paid. Such theories usually suggest that to these
people, money doesn't matter. Either because of a major
internet-driven shift in human nature favouring generosity towards
unknown strangers and similar forms of saintliness, or because of some
temporary excitement and enthusiasm for "programming-as-a-hobby",
these people are working selflessly for the benefit of others rather
than themselves.
Most theories, in other words, treat the phenomenon of Internet
free software - and free other things - as irrational.
The cooking-pot market model provides an alternative: these
internet pioneers are rational and as selfishly human as everyone
offline; however, they realise that publishing their software freely
benefits them. This model explains how people on the Internet
benefit from apparently "giving away" things; how rational
self-interest remains the prime motive in this new economy; and how
these benefits to people, and their contribution to their communities
in these intangible ways, can actually be measured.
Video4Linux
Implementation of LVM - a Logical Volume Manager for Linux
Advanced Linux Sound Architecture (ALSA) - The future for the Linux sound!?
Introduction
Soundcard and devices
Modularized design
perlin:/home/perex/alsa/alsa-driver # lsmod
Module Size Used by
snd-pcm1-oss 15820 0
snd-mixer-oss 3836 0
snd-card-dummy 6016 0 (unused)
snd-pcm1 22172 0 [snd-card-dummy]
snd-timer 10908 0 [snd-pcm1]
snd-mixer 27840 0 [snd-card-dummy]
snd-pcm 9772 0 [snd-card-dummy snd-pcm1]
snd 38464 1 [snd-card-dummy snd-pcm1 snd-timer snd-mixer snd-pcm]
The dummy driver provides a virtual soundcard. As you can see, there are six
kernel modules:
This module is the ALSA driver kernel. It contains a device multiplexor,
soundcard management, /proc information routines and a basic control
interface for detection of present interfaces and features.
This module contains basic support for PCM layers.
This module contains the native API implementation for the usual PCM devices.
This module is used, because the snd-pcm1 module provides slave timers.
This is main mixer module which provides native API.
This is the top level module. It also contains the mixer and PCM drivers.
This module is providing the additional OSS/Free PCM compatibility.
This module is providing the additional OSS/Free mixer compatibility.
perlin:/home/perex/alsa/alsa-driver # lsmod
Module Size Used by
snd-pcm1-oss 15820 0
snd-mixer-oss 3836 0
snd-card-trid4dwave 2600 0 (unused)
snd-seq-device 3356 1 [snd-card-trid4dwave]
snd-trident_dx_nx 9680 0 [snd-card-trid4dwave]
snd-pcm1 22172 0 [snd-trident_dx_nx]
snd-pcm 9772 0 [snd-card-trid4dwave snd-pcm1]
snd-timer 10908 0 [snd-pcm1]
snd-ac97-codec 21920 0 [snd-trident_dx_nx]
snd-mixer 27840 0 [snd-card-trid4dwave snd-trident_dx_nx snd-ac97-codec]
snd-mpu401-uart 3384 0 [snd-card-trid4dwave snd-trident_dx_nx]
snd-midi 17868 0 [snd-card-trid4dwave snd-mpu401-uart]
snd 38464 1 [snd-card-trid4dwave snd-seq-device snd-trident_dx_nx snd-pcm1 snd-pcm snd-timer snd-ac97-codec snd-mixer snd-mpu401-uart snd-midi]
Modules:
This module is providing the raw MIDI native and OSS/Free APIs.
This module manages the sequencer drivers (MPU401 in this case).
The PCM driver for the Trident chips.
The generic driver for AC'97 (audio codec) chips. It contains the mixer
code.
The generic driver for MPU-401 uarts.
Current status of native interfaces in the driver
The control interface allows to an application to obtain various
information from the driver without the exclusive locking of some feature.
It also offers the reading of the change/modify/add/remove events for the
universal switches.
The mixer (version 2) interface has very new design now. It does not
follow anything known. The mixer is described via control elements and
routes among them. It allows to describe very complicated audio
analog/digital mixers available in current soundcards. We have also
possibility to enhance this interface in each aspects. The mixer
interface has also a group control for the basic elements. This
control method was designed to provide the standard mixer behaviour
and to retain the compatibility with the OSS/Free mixer interface.
Both control methods (element & group) can be used concurrently.
The mixer interface also fully supports the change/modify/add/remove
notifications through events which can be obtained via the read()
function. It allows a perfect synchronization among more mixer
applications.
The PCM interface supports full duplex when hardware contains this
feature. The last added feature is multi open. When hardware is able
to mix more PCM streams concurrently, then the ALSA driver allows
the open call more times, until the resources are not exhausted.
The Raw MIDI interface is fully supported. It allows to read and write
unchanged data from the MIDI ports. These ports can connect either
external or internal devices.
The timer interface allows to use timers from soundcards. It also
offers a slave mode. It means that some piece of code from the
user space can be synchronized with any kernel device which uses
same timer. The PCM stream can be also used as a primary timer source.
It allows a perfect synchronization between a digital audio stream
and a MIDI stream.
The sequencer inside the ALSA driver is probably the most interesting
part of the ALSA driver, but it is still under development. The original
proposal from Frank van de Pol have been very enhanced and the current
code is able to drive 192 clients at same time. Each client has two
memory pools for input and output events. The features like event
merging, a client notification about the internal changes or changes
provoked with an another application are a matter of course.
This interface does not provide an abstract layer to applications
except the protocol identification. It is intended for hardware
which does not fit to any abstract interface like FX processors,
a special access to synthesizer chips etc.
Current status of OSS compatible interfaces in the driver
The OSS/Free mixer API is fully emulated.
The OSS/Free PCM API is emulated. A few applications have trouble with
this emulation. These trouble are mostly caused with wrong assumptions
of authors.
The OSS/Free raw MIDI API is emulated.
The level 1 sequencer API is emulated. The level 2 API is not emulated.
There is available only a few application for the level 2 interface.
The mixer code in detail
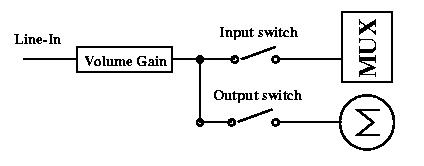
All elements show also routes among them inside the ALSA API. It's very
useful for the intuitive graphics visualization.
A lowlevel driver controls the single elements inside group to handle requests:
set volume level, set mute or capture source. To accomplish the situation,
one element can be in more groups (Input MUX is an example).
The PCM code in detail
Related code
The C ALSA library
The future
About the author
WWW links
[2] The Linux Ultra Sound Project - http://www.perex.cz/~perex/ultra/
[3] Open Sound System (OSS) Free - http://www.linux.org.uk/OSS
[4] Open Sound System (OSS) Programmer's Guide - http://www.opensound.com/pguide
[5] SuSE - http://www.suse.com
XFS on Linux
KOffice - an Office Suite for the K Desktop Environment
reiserfs
Deficencies in the UNIX-Design
The author
The making of Linux/ia64
Thoughts about init
INIT(8) Linux System Administrator's Manual INIT(8)
NAME
init - process control initialization
SYNOPSIS
/sbin/init {options}[[action]service{ops}]
DESCRIPTION
Init is the father of all processes. Its primary role is
to create processes from a script stored in the file
/etc/init.conf (see init.conf(5)). This file usually has
entries which cause init to spawn gettys on each line that
users can log in. It also controls autonomous processes
required by any particular system.
Due to the fact all daemons run with init as parent, only
init is notified when a daemon dies. So init ist the natu
ral process to handle all events of daemons, like start
ing, reloading, respawning etc. pp..
As a consequence /var/run/ is obsolete. /var/run/utmp and
/var/log/wtmp are considered obsolete, too.
SERVICES
A service is a software configuration of the system. Each
service may depend on other services running. So a depen
dency tree is spawned to keep the system running.
Each service can be up or down (or on the way to reach
such a final state). The service starts with an call sec
tion, waits for all needs to come up and execute the start
section to come up itself. The stop section is executed
to bring the service down. If a action on starting fails
(return anything beside 0), the service will go down.
Daemons can be started by remembering the process ID in a
variable. If such a daemons dies, a approbriate dead sec
tion is executed. Of course the variable is available to
other commands i.e. to send the process a signal.
The reload section is only executed on user's request. If
no reload section is defined, the service is stopped and
restarted.
BOOTING
After init is invoked as the last step of the kernel boot
sequence, it looks for the file /etc/init.conf and tries
to parse it. If this fails, init stops.
The first service in /etc/init.conf is the startup
default. If an argument was given to init, the named
23 March 1999 1
INIT(8) Linux System Administrator's Manual INIT(8)
service is started instead of this default.
CHANGING SERVICES
xxx
ENVIRONMENT
Init sets the following environment variables for all its
children:
INIT_VERSION
As the name says. Must not used to determine if a
script runs directly from init. Use getppid(2)
instead.
INTERFACE
xxx
SIGNALS
Init reacts to several signals: xxx
FILES
/etc/init.conf
WARNINGS
Init assumes that daemons do not try to fork to detach.
There is no need for such behavior.
AUTHOR
Lutz Donnerhacke <Lutz.Donnerhacke@Jena.Thur.De> due to a
request of Frank Klemm <pfk@uni-jena.de>.
The Debian Build-Daemon
Introduction
Overview
Outline of Operation
Applications and Future
Credits
Linux Security for Programmers, Crackers and Managers
Tomorrow, it might be Linux.
Author info:
MOSIX
FreeS/WAN IPsec implementation for Linux
The author
MERGEMEM
1 Motivation
2 Memory sharing
Mergemem
Mergemem finds equal pages in running processes, frees the redundant
pages, and gives all participating processes a read only reference
to the remaining page. The running processes are not affected, and
if there is a write operation to a shared page, the normal copy-on-write
takes place.
3.1 mergemod, the kernel module
3.2 mmlib, the clue layer
3.3 mergemem, the user-level-program
4 Impact on architectural level
5 Status
The first implementation was based on Linux 2.0 and checksum calculation
was carried out in kernel mode. It was in use at the Vienna University
of Technology for a prolog class for about 4 months. The installation
consists of about 20 X-terminals connected to a single server, and
every student ran emacs and prolog. Mergemem was a great success in
this environment, but unfortunately we were not allowed to collect
performance data during the term.
We are currently working on a new implementation as described in Section
mergemem, and it is close to release (probably in August). It
is based on Linux 2.2 and already supports SMP systems.
6 Sample Results
* Spread Sheet from Java JDK 1.1.3
+--------------------------+---------+
| 1st Instance | 12488KB |
+--------------------------+---------+
| further instance | +7612KB |
+--------------------------+---------+
| merging | -5160KB |
+--------------------------+---------+
* SICStus Prolog
+--------------------------+--------+
| 1st Instance | 2216KB |
+--------------------------+--------+
| further instance | +964KB |
+--------------------------+--------+
| merging | -880KB |
+--------------------------+--------+
7 Application scenarios
8 References
http://www.ist.org/mergemem/,
http://www.complang.tuwien.ac.at/~ulrich/mergemem/
Netfilter: Packet Mangling in 2.4
WINE
NIS and NIS+ for Linux
The protocol, implementation and plans for the future
The LinuxDirector VirtualServer Project
All for one and one for all
Final talk
Webmaster
Last modified: Thu Sep 16 14:33:48 CEST 1999